| 121. | Introduction to Out of Time Order Correlators (OTOCs)(2025) | (quantumcomputer.blog) |

|
Quantum Echoes is a quantum computational task that measures a novel family of observables called Out of Time Order Correlators (OTOCs). | |
| 3 points by rolph 4 days ago | 0 comments |
| 122. | Raspberry Pi Pico 2 at 873.5MHz with 3.05V Core Abuse | (learn.pimoroni.com) |
|
|
Adventures with dry ice and RP2350 - how fast can it go? – Pimoroni Learning Portal | |
| 4 points by Lwrless 2 days ago | 0 comments |
| 123. | Cord: Coordinating Trees of AI Agents | (june.kim) |
|
|
AI agents are good at doing one thing at a time. Give Claude a focused task and it performs. But real work isn’t one task. It’s a tree of tasks with dependen... | |
| 7 points by gfortaine 2 days ago | 0 comments |
| 124. | I found a useful Git one liner buried in leaked CIA developer docs | (spencer.wtf) |

|
How to delete all merged git branches locally with a single command. This one-liner has been in my zshrc since 2017 — I found it buried in the CIA's Vault7 l... | |
| 14 points by spencerldixon 2 days ago | 0 comments |
| 125. | Cloudflare outage on February 20, 2026 | (blog.cloudflare.com) |
|
|
Cloudflare suffered a service outage on February 20, 2026. A subset of customers who use Cloudflare’s Bring Your Own IP (BYOIP) service saw their routes to the Internet withdrawn via Border Gateway Protocol (BGP). | |
| 4 points by nomaxx117 1 day ago | 0 comments |
| 126. | Across the US, people are dismantling and destroying Flock surveillance cameras | (bloodinthemachine.com) |

|
Anger over ICE connections and privacy violations is fueling the sabotage. PLUS: 10,000 drivers call on Uber to repay stolen wages, a man is arrested at a public hearing about a data center and more. | |
| 5 points by latexr 2 days ago | 1 comments |
| 127. | macOS's Little-Known Command-Line Sandboxing Tool | (igorstechnoclub.com) |

|
||
| 19 points by Igor_Wiwi 1 day ago | 2 comments |
| 128. | Reading the undocumented MEMS accelerometer on Apple Silicon MacBooks via iokit | (github.com) |
|
|
reading the undocumented mems accelerometer + gyroscope on apple silicon macbooks via iokit hid - olvvier/apple-silicon-accelerometer | |
| 6 points by todsacerdoti 3 days ago | 0 comments |
| 129. | The Big Brother v3.0 is a weaponized OSINT platform | (github.com) |
|
|
The Big Brother V3.0 is a weaponized OSINT platform featuring username enumeration (473+ platforms), quad-vector visual intelligence, Sky Radar tracking, crypto wallet analysis, SSL intelligence, digital footprint reconstruction, EXIF extraction, advanced dorking, and network reconnaissance. - chadi0x/TheBigBrother | |
| 5 points by mnky9800n 7 hours ago | 1 comments |
| 130. | The path to ubiquitous AI (17k tokens/sec) | (taalas.com) |
|
|
By Ljubisa Bajic Many believe AI is the real deal. In narrow domains, it already surpasses human performance. Used well, it is an unprecedented... | |
| 36 points by sidnarsipur 2 days ago | 7 comments |
| 131. | Electric bikes and mopeds are cutting demand for oil more than electric cars | (theconversation.com) |

|
Electric vehicles get all the press – but it’s the smaller unsung two wheelers cutting oil demand the most. | |
| 5 points by doener 8 hours ago | 0 comments |
| 132. | MeshTNC is a tool for turning consumer grade LoRa radios into KISS TNC compatib | (github.com) |
|
|
MeshTNC is a tool for turning consumer grade LoRa radios into KISS TNC compatible packet radio modems - datapartyjs/MeshTNC | |
| 5 points by todsacerdoti 1 day ago | 0 comments |
| 133. | Tesla Begins Production of Cybercab | (barrons.com) |
|
|
||
| 4 points by lateforwork 6 hours ago | 4 comments |
| 134. | Holo v0.9: A Modern Routing Stack Built in Rust | (github.com) |
|
|
Holo is a suite of routing protocols designed to support high-scale and automation-driven networks. - Release Holo v0.9.0 · holo-routing/holo | |
| 4 points by WarOnMosquitoes 19 hours ago | 1 comments |
| 135. | Met police using AI tools supplied by Palantir to flag officer misconduct | (theguardian.com) |

|
Exclusive: Police Federation condemns deployment of US firm’s tech to analyse behaviour as ‘automated suspicion’ | |
| 3 points by helsinkiandrew 19 hours ago | 0 comments |
| 136. | Jeffery Epstein met with m00t in 2011 | (archive.ph) |
|
|
||
| 5 points by nipponese 2 hours ago | 1 comments |
| 137. | Unsung heroes: Flickr's URLs scheme | (unsung.aresluna.org) |
|
A blog about software craft and quality | |
| 4 points by bookofjoe 17 hours ago | 0 comments |
| 138. | Making frontier cybersecurity capabilities available to defenders | (anthropic.com) |
|
|
Claude Code Security is one step towards our goal of more secure codebases and a higher security baseline across the industry. | |
| 4 points by surprisetalk 2 days ago | 0 comments |
| 139. | Large Language Model Reasoning Failures | (arxiv.org) |
|
|
Abstract page for arXiv paper 2602.06176: Large Language Model Reasoning Failures | |
| 4 points by T-A 1 day ago | 1 comments |
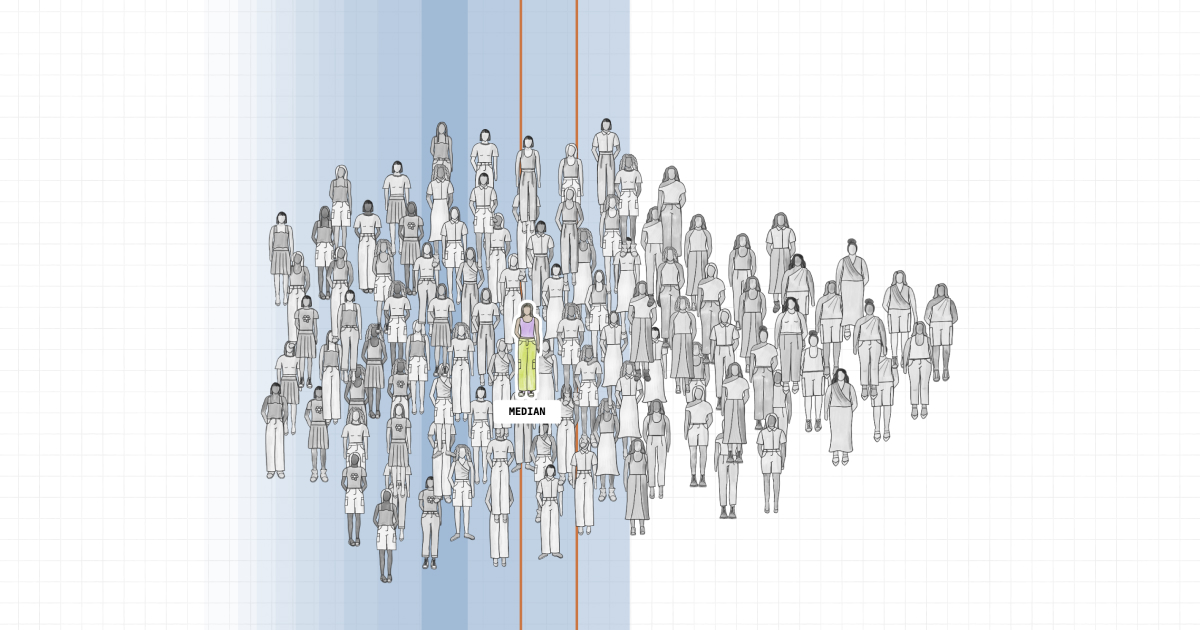
| 140. | Womens Sizing | (pudding.cool) |
|
The inter-generational struggle to find clothes that fit more than a tiny portion of women | |
| 9 points by zdw 4 days ago | 0 comments |
| 141. | Fighting games have a product design problem | (cthor.me) |
|
|
||
| 4 points by bentcorner 1 day ago | 1 comments |
| 142. | AI is not a coworker, it's an exoskeleton | (kasava.dev) |
|
|
Companies that treat AI as an autonomous agent are disappointed. Those that treat it as an exoskeleton—an amplifier of human capability—are seeing transformative results. Here's the framework. | |
| 8 points by benbeingbin 3 days ago | 2 comments |
| 143. | Jordi Bonada (MTG): 20 years of singing voice synthesis at the MTG [video] | (youtube.com) |

|
In this talk, we will overview our research in singing synthesis for the last two decades, and the impact deep learning has brought in. We will see how the d... | |
| 5 points by q7m 7 hours ago | 0 comments |
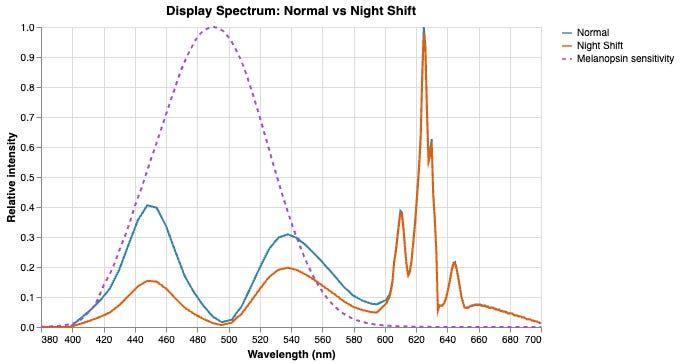
| 144. | Blue light filters don't work | (neuroai.science) |
|
Why controlling total luminance is a better bet | |
| 6 points by pminimax 2 days ago | 2 comments |
| 145. | An Unbothered Jimmy Wales Calls Grokipedia a 'Cartoon Imitation' of Wikipedia | (gizmodo.com) |
|
|
Speaking at India's AI Impact Summit, Wales went in on the hallucinating pretender to the throne. | |
| 4 points by rbanffy 13 hours ago | 1 comments |
| 146. | Training a Human Takes 20 Years of Food | (news18.com) |

|
Altman says debates on AI power use overlook that human intelligence also requires years of life, education and resources to develop. | |
| 4 points by Aldipower 13 hours ago | 0 comments |
| 147. | A 26-Gram Butterfly-Inspired Robot Achieving Autonomous Tailless Flight | (arxiv.org) |
|
|
Abstract page for arXiv paper 2602.06811: A 26-Gram Butterfly-Inspired Robot Achieving Autonomous Tailless Flight | |
| 3 points by Terretta 18 hours ago | 0 comments |
| 148. | Child's Play: Tech's new generation and the end of thinking | (harpers.org) |
|
|
Tech’s new generation and the end of thinking | |
| 6 points by ramimac 2 days ago | 3 comments |
| 149. | Stranded Overnight: Lufthansa Passengers Not Allowed to Deplane A320neo | (simpleflying.com) |
|
|
||
| 4 points by gynecologist 9 hours ago | 0 comments |
| 150. | US plans online portal to bypass content bans in Europe and elsewhere | (reuters.com) |
|
|
||
| 12 points by c420 4 days ago | 1 comments |